Understanding Embeddings
The rise of vector databases has defined a whole new sector in technology. Whether it’s Pinecone, Qdrant, Weaviate or ChromaDb, vendors have just appeared on the landscape seemingly out of nowhere and now it seems like every other post on your favourite social media channel is talking about these things like they’re a critical part of technology infrastructure. What’s the thing that underpins this technology and makes it all possible? Embeddings. In this article we’ll explore where they came from, what they are and why they’re so valuable when it comes to creating personalised AI solutions.

Introduction
The rise of vector databases has defined a whole new sector in technology. Whether it’s Pinecone, Qdrant, Weaviate or ChromaDb, vendors have just appeared on the landscape seemingly out of nowhere and now it seems like every other post on your favourite social media channel is talking about these things like they’re a critical part of technology infrastructure. What’s the thing that underpins this technology and makes it all possible? Embeddings. In this article we’ll explore where they came from, what they are and why they’re so valuable when it comes to creating personalised AI solutions.
The problem
For those of us old enough to remember there was a time when finding data from a computer system was limited to running a query on a database. These databases were designed to store structured data like sales orders, financial accounts, or customer cases. And to get information out we had to write queries - this was so common that an entire language was created for this one task - SQL. We even defined roles for people whose sole job it was was to make sure that these queries would be as efficient as possible - DBA’s.
Now this was all fine, but what if the data you had wasn’t structured and didn’t fit neatly into a database? Or what if you weren’t completely sure of the words that were in the Opportunity that you’re trying to find? Well tough luck basically.
That was until about 20 or so years ago when Google released the Enterprise Search - a physical box that had the power to search your corporate data using a Google search algorithm. Now - we don’t need to know the exact words or write queries in different languages - we can just make a free text search and Google will do the rest and find relevant data based on keywords.

Google Enterprise Search
Overtime this spawned a number of solutions of which today “Elastic Search” is perhaps the best known. However our ability to find relevant information is still limited by our ability to find information based on keywords. If you want to account for spelling typos then you have to develop rules that will do that for you. If only there was a way in which our queries or questions could find answers by just inferring what we mean in the question and not dependent on us using the right keywords or spelling things correctly? Enter the embedding.
Semantics
The key idea of embeddings is that it groups things together based on their semantic similarity, but unlike traditional storage systems we don’t find information based on the textual information that we are looking for instead we find information using lists of number that are called vectors that you can think of as being a coordinate system.
Vectors as Coordinates
When I was a kid I was in the scouts, and one of the things I used to really enjoy was orienteering - which for the Gen Z’s amongst us is a way of getting from A to B before we had phones with Google maps on them. We were given a map and a compass and told where we had to get to on the map which was described using a set of numbers. The maps a sectioned into grids and the coordinates described the location of which grid we needed to get to. With this coordinate system, places that are closer together geographically have coordinates that are closer together numerically.
Imagine that I want to find pubs in the village of Crondall, Hampshire. If I had a list of all the coordinates of all pubs in the UK, then one way to tackle this would be to find the coordinates of the centre of Crondall and then lookup in our list the pubs whose coordinates are numerically closest to the village centre’s coordinates. We’re guaranteed to get pubs that are in the village and we’ll even be able to calculate how far each pub is from the village centre.
Embeddings are nothing more than a coordinate system for things that are separated by their semantic distance rather than their geographical distance and a vector database is the map that holds all the things that we care about in this semantic coordinate system.
Semantic Embeddings
Let’s put to one side how these embeddings are created in the first place and just assume that we have some special lookup that can tell us for any phrase or question what the embedding is. In this scenario the usage of semantic search is exactly the same as a geographical search. We have a question and convert it into coordinates ( embedding ), and we then query our vector database to find the items of things that are closest to that question embedding. Because things that are closest together have similar semantic meanings our search results are all semantically similar to the question. So questions like “I want to find somewhere for a drink in Crondall” will be similar to “Can you tell me what pubs are in North East Hampshire". Two questions which are very different from a keyword search point of view, but are somewhat similar from a semantic perspective.
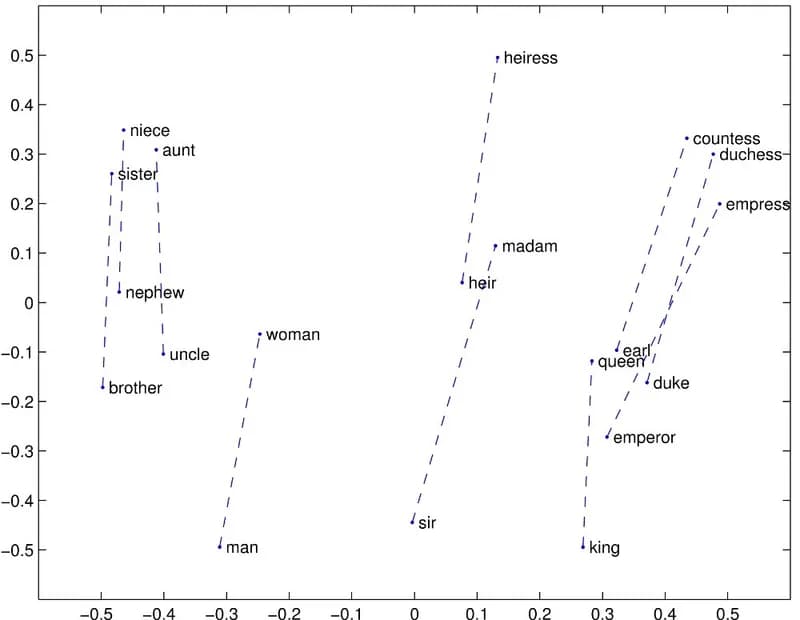
GloVe - An early embedding model from 2014
The early embedding models were word based, so an embedding value was generated for each word. The figure is from GloVe and shows how certain words are arranged in their coordinate space. In this particular example the dotted lines link the words that are related by sex or gender. Notice the pattern, all the male terms are below the female equivalent and the distance separating the male and female terms are similar. So to answer a question like “if woman is to man then queen is to what?” it’s actually very simple maths:
king = queen - (woman - man)
This shows that embeddings can even capture relationships between words. These properties of embeddings make them very powerful and as research has developed the sophistication of these embedding models have increased so that now whole passages of text can be given an embedding by an embedding model.
Uses
Talk to your company documents
One of the most widely discussed uses of embedding based vector databases is in Retrieval Augmented Search, which are AI systems that enable chat with private data like your corporate documents. A traditional chatgpt like system can be enhanced to first search the vector database with the users question, retrieving all the relevant pieces of information, this is then in turn entered into the AI LLM model along with the users question and the LLM is asked to use the retrieved information in generating its answer.
Recommendation Systems
Systems like Netflix use embeddings to find films that are similar to ones that you have watched and liked. You can actually use embeddings to find other users who are similar to you and use a combination of users and films to tailor the recommendations to the individuals tastes.
Anomaly Detection
By converting data points like network traffic or transaction logs into embeddings, normal operational behaviour forms a dense cluster in the vector space. Any new data point that falls far outside of this cluster can be instantly flagged as an anomaly or a potential threat, enabling much faster detection of fraud or security breaches.
Process Automation
Embeddings can represent different steps or components within a business workflow. By analyzing these representations, AI systems can identify highly similar, repetitive tasks across different departments. This allows businesses to pinpoint the most impactful opportunities for automation, streamlining operations and freeing up employee time for more complex work.
Recruitment Job Matching
The hiring process can be significantly streamlined using embeddings. A candidate's CV and a job description are each converted into a vector. A vector database can then be used to find the CVs that are most similar to the job description, moving beyond simple keyword matching to understand the semantic meaning of the text. This provides a ranked list of candidates who are the best fit for the role based on their experience and skills.
Code Search
For developers, finding the right piece of code in a large repository can be a major challenge. Code search powered by embeddings allows developers to search using natural language to describe what they want the code to do. The system converts this query into an embedding and searches the vector database for code snippets that have a similar vector, effectively translating human intent into a code discovery tool.
Conclusion
Embeddings are an incredibly powerful bow in our AI armoury and can transform AI systems from being clever but very generic systems into things that are personalised to individuals or processes.
If you’d like to discuss how you can use embeddings to make personalised AI then we’d love to hear from you. Contact us